I am trying to setup two routers in VRRP HA with version 1.4 and have setup IPsec vpn and then configuring vti interfaces. Later would like to achieve bgp with VRRP.
Now VRRP works fine with eth0 and eth1 but when I configure VRRP with vti, the VTI on secondary does not come up. and “show vrrrp” shows FAULT on both
It shows UP on Primary but it does not come up on secondary
So my question is can VRRP work with VTI? Can I configure VTI VRRP BGP and that will work as well?
VRRP does things at both layer 2 & 3 in order to work - a VTI is a layer 3 interface and cannot support the MAC magic VRRP wants to do.
What specifically are you trying to achieve with redundant IPs inside a VTI tunnel?
When dynamic routing protocols are in play (like BGP), most use cases for VRRP disappear - it is most useful when you have devices wanting a static single IP to route towards, so you need some way to keep it up even if a device fails.
With BGP/OSPF/etc, you would just configure the relevant devices to follow the best path and let the routing protocol(s) figure that out and detect outages.
Well as I said I wanted to achieve HA failover between two devices - Those are configured to avoid single device failure. If not VTI then how can we configure HA between devices
I think I remember replying to a couple of your posts before - I’m just trying to figure out your use case for all this. You’re asking very specific questions that don’t entirely line up with a larger picture.
First off - what are you trying to achieve with this redundancy? It looks like a site-to-site VPN between 2 sites? Why does it need to be redundant? Resilient infrastructure is a noble goal but not an end goal.
Second, what can or do you have available? Multiple internet/WAN links? Cloud tenancies/VPS? Network equipment at each end? Just in rough terms is fine, especially if this is still just a dummy-up or in planning stages.
I have HO and 4 branches. At HO I have two ISP links and same with branches; however since all the my severs are HO are very critical like SAP/File Server; I am building a scenario which is more resilient from ISP failure as well as device failure.
So ISP failure can be sorted out with redundant tunnel or with dynamic routing however how about device failure at HO. If my vyos router fails all branches will be down hence trying to build a redundant hardware or HA with Vyos and hence searching for many other options.
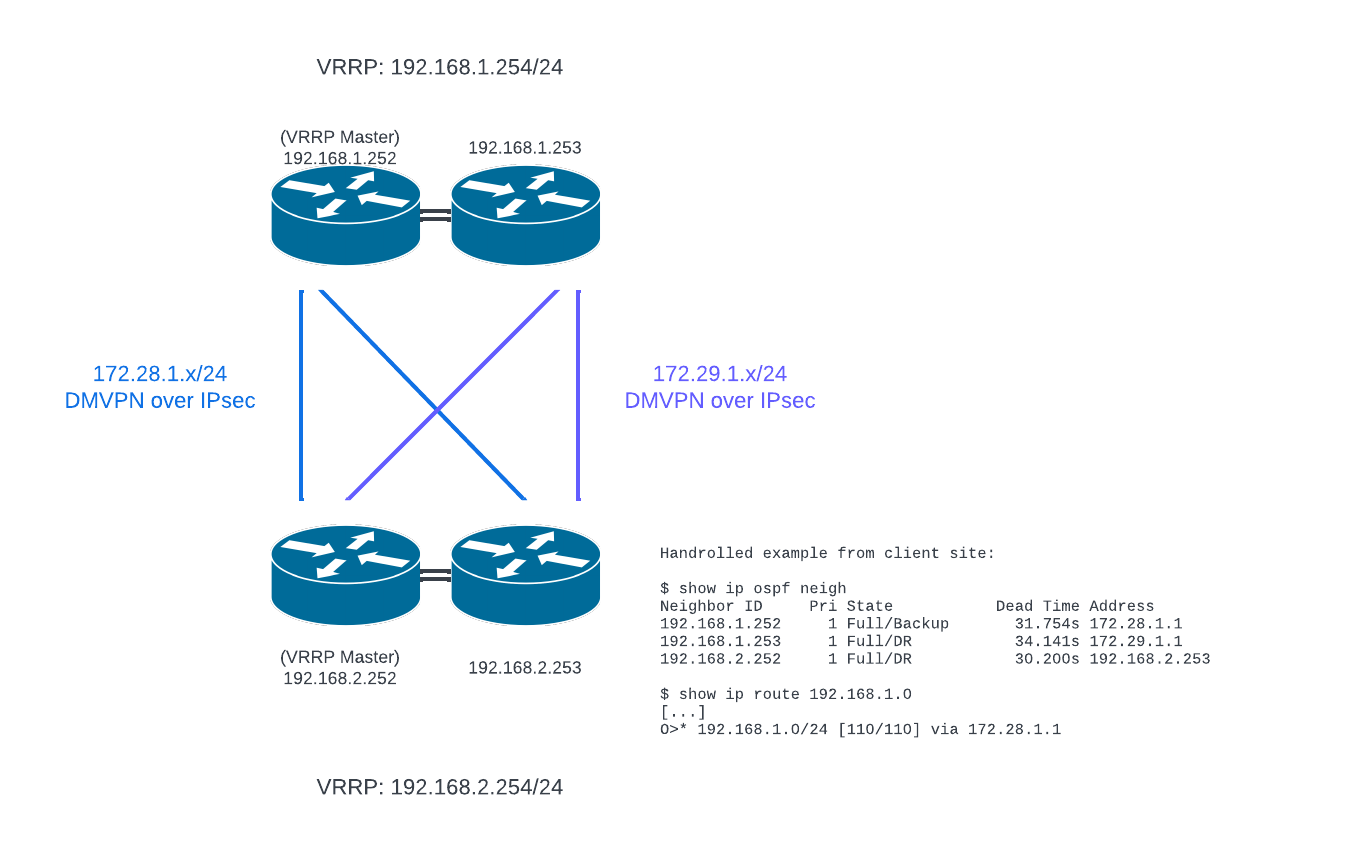
VyOS pair with VRRP-redundant ethernet interface in HO (facing inwards)
VyOS pair have dynamic routing adjacency (direct OSPF or BGP between themselves)
One VyOS per WAN link, no VRRP
If you have a /29 or wider, you can multihome both for Internet failover and LB, but you do not want to terminate any VPNs on virtual or shared IPs.
Establish a redundant VPN mesh - I would use 2 DMVPNs hubbed on head office, one per interface. There are potentially better options if everything is VyOS across the whole WAN, but I haven’t had the opportunity to play with Wireguard or similar in production.
Each client site will connect to both DMVPN hub IPs on separate tunnels
Ideally, you’d run this from independent multi-homing WAN interfaces on the client side as well, but not as critical as the HO hubs
The idea is to have all tunnels up and ready at all times. Dynamic routing can see what’s available on each path and make its decision.
You want at least 2 independent meshes/tunnels - you do not want the VPN layer trying to handle multihoming redundancy
Establish dynamic routing across the mesh - I would use straight OSPF for simplicity, but if you have more complex requirements (like route filtering between sites) BGP would be the choice.
For OSPF, you don’t need to worry at all about redundant IPs and dummy interfaces on the mesh - discovery handles everything, whether point-to-point static tunnels or multicast over a mesh. Ensure HO routers can see all tunnel interfaces as neighbours for each remote site and vice versa.
For BGP, establish sessions between sites and HO over each mesh. This one can get a bit too complex for a handful of bullet points, but is similar in function to the OSPF design.
Client side routing can be of a similar design - you can have multiple devices or VMs, multiple WANs, but their VPNs need to be configured appropriately to connect back to HO’s hub interfaces.
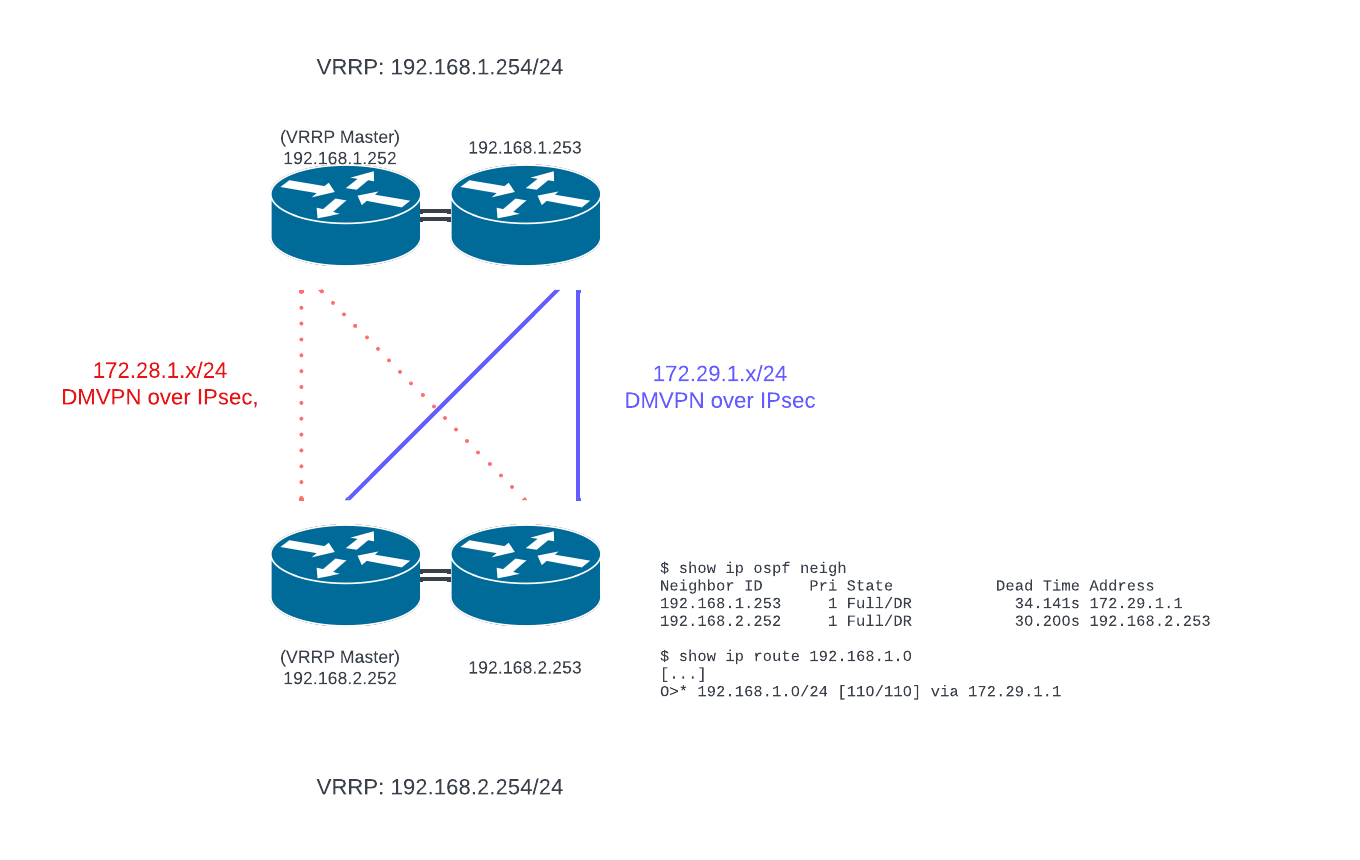
Any link failure will result in the withdrawal of routes over those tunnels and traffic switching to another available path. Dynamic routing protocols will detect dead neighbours and react appropriately.
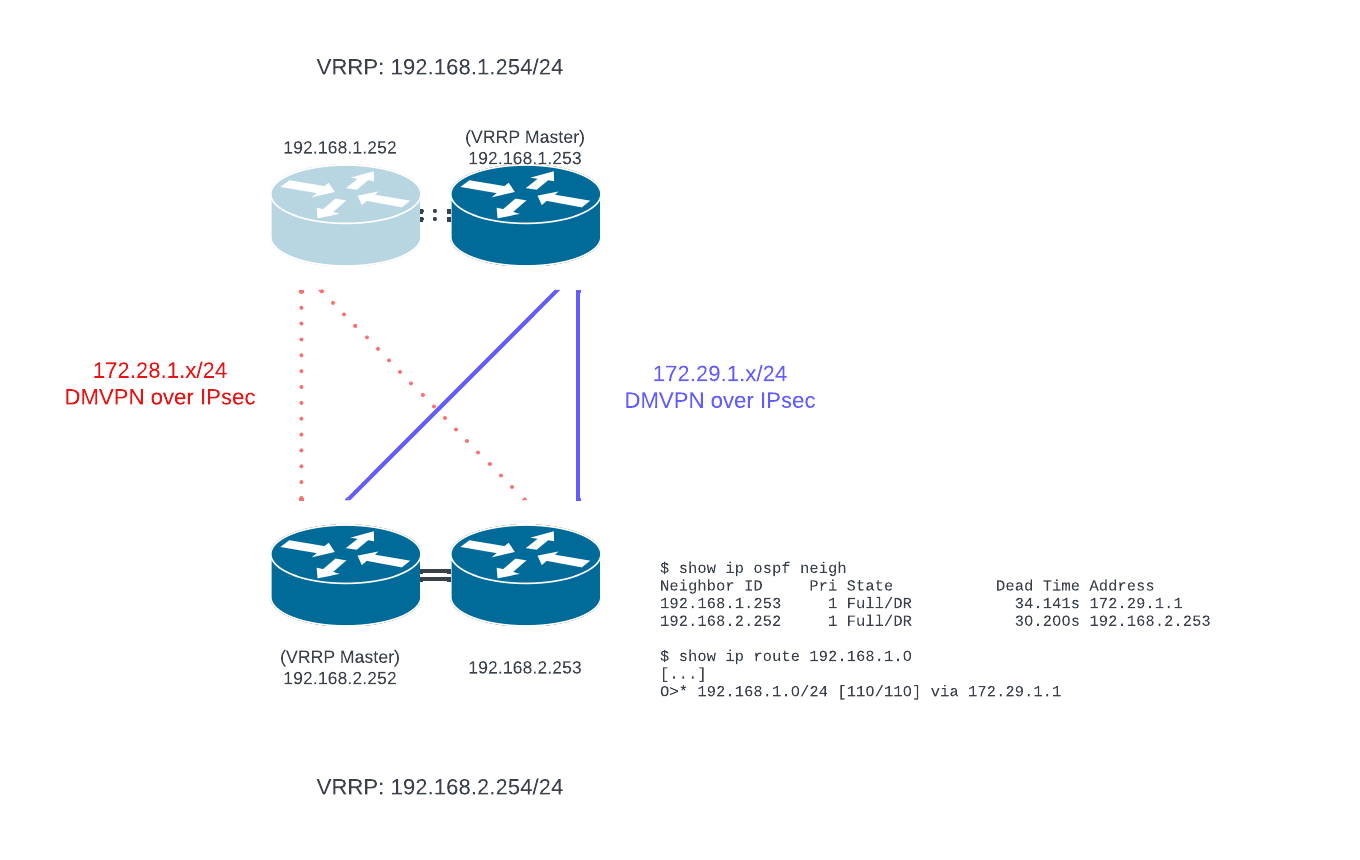
Any equipment failure will result in the same, it’s no different to when a link goes down - the routing protocol sees the other end stop responding, so it stops using it for traffic.
You will not need any static routing or similar in the middle, on the mesh - dynamic routing protocols figure out what is available and on what path, so there is no need for single IPs on routers to point things at.
You may want to use loopbacks/dummy interfaces for the BGP scenario and combine it with OSPF or similar. This is the only case in which you’ll be running sessions across the mesh between dummy interfaces.
If the link goes down, the router 1.252 can still see a path via its partner to the site, so it is not a problem that it still holds the VRRP IP internal devices will be using as a gateway.
If the router goes down entirely, it’s not that different to a link outage as far as the client site is concerned. Traffic still goes via the alternate path.
You can use OSPF costing to prefer one path over another on each side or get fancy with BGP route-maps for prefs and weights. ECMP for bandwidth aggregation may be doable but I wouldn’t recommend it if resilience is the main goal.
Note that the DMVPN would run over separate WAN interfaces, I haven’t included IPs for them in the diagram.