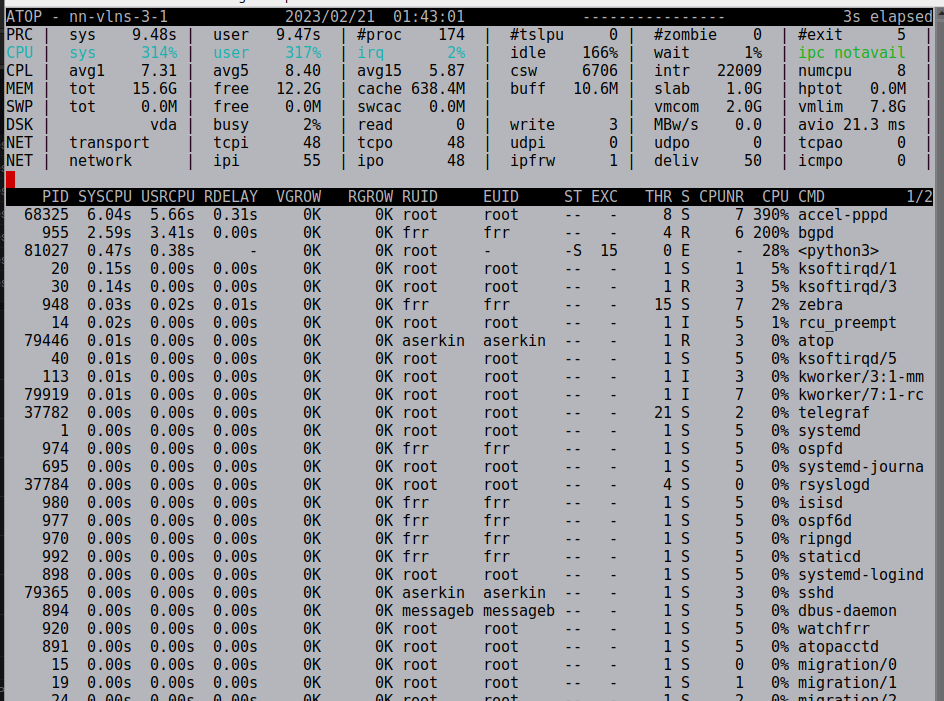
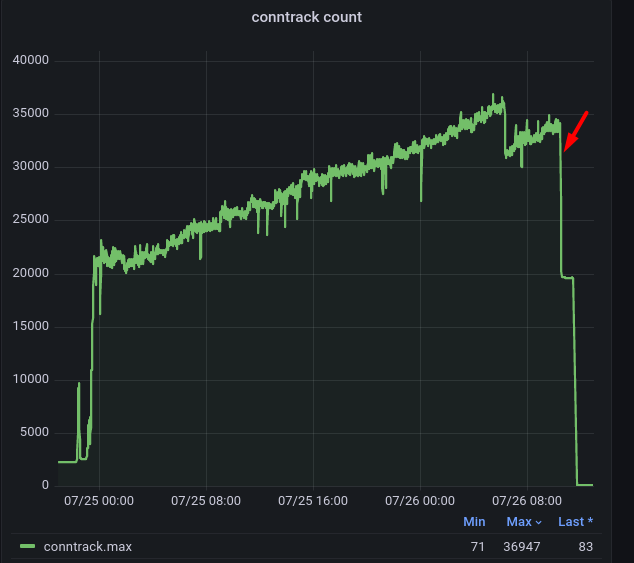
I did some more attempts to start the service with vyos 1.4 rolling releases up to yesterday image. The behavior looks the same.
The node serves 10k+ l2tp subscribers during an hour and a half until routes suddenly disappear from kernel.
Peering is organized like this:
IPv4 Unicast Summary (VRF default):
BGP router identifier 10.228.134.1, local AS number 64826 vrf-id 0
BGP table version 2001
RIB entries 1788, using 335 KiB of memory
Peers 4, using 2898 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.228.134.32 4 39374 16520 12763 0 0 0 17:43:25 111 2 BBR-x-1 vrf AAA
10.228.134.34 4 39374 16506 12763 0 0 0 17:43:25 111 2 BBR-x-2 vrf AAA
10.228.134.36 4 39374 16460 12763 0 0 0 17:43:25 219 2 BBR-x-1 vrf LNS
10.228.134.38 4 39374 16481 12763 0 0 0 17:43:25 219 2 BBR-x-2 vrf LNS
Total number of neighbors 4
IPv4 VPN Summary (VRF default):
BGP router identifier 10.228.134.1, local AS number 64826 vrf-id 0
BGP table version 0
RIB entries 2933, using 550 KiB of memory
Peers 2, using 1449 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.5.72.1 4 39374 4410101 13230 0 0 0 17:43:22 65270 232 BBR1 vpnv4
10.5.72.2 4 39374 4380640 13230 0 0 0 17:43:22 65269 232 BBR2 vpnv4
Total number of neighbors 2
IPv4 Labeled Unicast Summary (VRF default):
BGP router identifier 10.228.134.1, local AS number 64826 vrf-id 0
BGP table version 3
RIB entries 5, using 960 bytes of memory
Peers 2, using 1449 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.228.134.40 4 39374 1603 1067 0 0 0 17:43:25 635 2 BBR1 ipv4 LU
10.228.134.42 4 39374 1611 1067 0 0 0 17:43:25 635 2 BBR2 ipv4 LU
where first group of four peers provide connectivity to AAA servers and L2TP access concentrators.
The last group of peers used for label unicast peering. From 10.228.134.40, 10.228.134.42 we receive routes to peers 10.5.72.1,10.5.72.2 used for vpnv4:
aserkin@lns:~$ show ip route 10.5.72.1
Routing entry for 10.5.72.1/32
Known via “bgp”, distance 20, metric 0, best
Last update 17:59:00 ago
- 10.228.134.40, via eth3, label 48203, weight 1
- 10.228.134.42, via eth4, label 48403, weight 1
When the problem occured the routes received from LU peers have disappeared from kernel for unknown reason. After that peering with vpnv4 nodes went down and dropped all vpnv4 connectivity:
IPv4 Unicast Summary (VRF default):
BGP router identifier 10.228.134.1, local AS number 64826 vrf-id 0
BGP table version 2512
RIB entries 1788, using 335 KiB of memory
Peers 4, using 2898 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.228.134.32 4 39374 2503 1891 0 0 0 02:37:23 111 2 BBR-x-1 vrf AAA
10.228.134.34 4 39374 2523 1891 0 0 0 02:37:23 111 2 BBR-x-2 vrf AAA
10.228.134.36 4 39374 2467 1891 0 0 0 02:37:23 219 2 BBR-x-1 vrf LNS
10.228.134.38 4 39374 2466 1891 0 0 0 02:37:23 219 2 BBR-x-2 vrf LNS
Total number of neighbors 4
IPv4 VPN Summary (VRF default):
BGP router identifier 10.228.134.1, local AS number 64826 vrf-id 0
BGP table version 0
RIB entries 2911, using 546 KiB of memory
Peers 2, using 1449 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
> 10.5.72.1 4 39374 493587 165618 0 0 0 00:15:47 Active 0 BBR1 vpnv4
> 10.5.72.2 4 39374 433783 165618 0 0 0 00:15:48 Active 0 BBR2 vpnv4
Total number of neighbors 2
IPv4 Labeled Unicast Summary (VRF default):
BGP router identifier 10.228.134.1, local AS number 64826 vrf-id 0
BGP table version 3
RIB entries 5, using 960 bytes of memory
Peers 2, using 1449 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.228.134.40 4 39374 510 161 0 0 0 02:37:23 635 2 BBR1 ipv4 LU
10.228.134.42 4 39374 509 161 0 0 0 02:37:23 635 2 BBR2 ipv4 LU
Total number of neighbors 2
The problem can be fixed only by node reboot. Or i just do not know how to do the fix)
Why the routes received from FRR can disappear suddenly? What can be the reason?
aserkin@lns:$ show ip route 10.5.72.1
aserkin@lns:$ show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, F - PBR,
f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
C>* 10.5.28.10/32 is directly connected, l2tp6313, 00:37:57
C>* 10.228.134.0/32 is directly connected, dum0, 02:36:48
C>* 10.228.134.1/32 is directly connected, dum1, 02:36:29
C>* 10.228.134.2/32 is directly connected, dum2, 02:36:44
C>* 10.228.134.32/31 is directly connected, eth1.616, 02:36:06
C>* 10.228.134.34/31 is directly connected, eth2.617, 02:36:07
C>* 10.228.134.36/31 is directly connected, eth1.618, 02:36:06
C>* 10.228.134.38/31 is directly connected, eth2.619, 02:36:06
C>* 10.228.134.40/31 is directly connected, eth3, 02:36:07
C>* 10.228.134.42/31 is directly connected, eth4, 02:36:08