Hi, just to warn everyone if using VyOS 1.2.7 LTS image with snmp, bgp and vrrp.
At the moment I have exactly the same behaviour as described in this topic.
After some time of working, bgpd, vrrpd and snmpd stops, and in the log I can see following messages:
ul 13 10:39:02 dp-router1 bgpd[1188]: snmp[info]: AgentX master disconnected us, reconnecting in 15
Jul 13 10:39:09 dp-router1 ripd[1196]: [EC 100663310] snmp[warning]: AgentX master agent failed to respond to ping. Attempting to re-register.
Jul 13 10:39:13 dp-router1 zebra[1183]: [EC 100663310] snmp[warning]: AgentX master agent failed to respond to ping. Attempting to re-register.
Jul 13 10:39:15 dp-router1 ospf6d[1210]: [EC 100663310] snmp[warning]: AgentX master agent failed to respond to ping. Attempting to re-register.
Jul 13 10:39:18 dp-router1 Keepalived_vrrp[3688]: AgentX master agent failed to respond to ping. Attempting to re-register.
Jul 13 10:39:21 dp-router1 ripd[1196]: [EC 100663313] SLOW THREAD: task agentx_timeout (7efe81593b80) ran for 18018ms (cpu time 0ms)
Jul 13 10:39:22 dp-router1 ospfd[1204]: [EC 100663310] snmp[warning]: AgentX master agent failed to respond to ping. Attempting to re-register.
Jul 13 10:39:23 dp-router1 bgpd[1188]: [EC 100663313] SLOW THREAD: task agentx_timeout (7fae45866b80) ran for 6006ms (cpu time 0ms)
Jul 13 10:39:25 dp-router1 zebra[1183]: [EC 100663313] SLOW THREAD: task agentx_timeout (7fb83d47ab80) ran for 18017ms (cpu time 0ms)
Jul 13 10:39:27 dp-router1 ospf6d[1210]: [EC 100663313] SLOW THREAD: task agentx_timeout (7f1dba1a2b80) ran for 18018ms (cpu time 0ms)
Jul 13 10:39:34 dp-router1 ospfd[1204]: [EC 100663313] SLOW THREAD: task agentx_timeout (7fd994b84b80) ran for 18017ms (cpu time 0ms)
Jul 13 10:41:03 dp-router1 watchfrr[1153]: [EC 268435457] bgpd state -> unresponsive : no response yet to ping sent 90 seconds ago
Jul 13 10:41:03 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 1438]: /usr/lib/frr/watchfrr.sh restart bgpd
Jul 13 10:41:10 dp-router1 watchfrr[1153]: [EC 268435457] ripd state -> unresponsive : no response yet to ping sent 90 seconds ago
Jul 13 10:41:10 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 1515]: /usr/lib/frr/watchfrr.sh restart ripd
Jul 13 10:41:12 dp-router1 watchfrr[1153]: [EC 268435457] ospf6d state -> unresponsive : no response yet to ping sent 90 seconds ago
Jul 13 10:41:12 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 1542]: /usr/lib/frr/watchfrr.sh restart ospf6d
Jul 13 10:41:15 dp-router1 watchfrr[1153]: [EC 268435457] zebra state -> unresponsive : no response yet to ping sent 90 seconds ago
Jul 13 10:41:19 dp-router1 watchfrr[1153]: [EC 268435457] ospfd state -> unresponsive : no response yet to ping sent 90 seconds ago
Jul 13 10:41:23 dp-router1 watchfrr[1153]: Warning: restart bgpd child process 1438 still running after 20 seconds, sending signal 15
Jul 13 10:41:23 dp-router1 watchfrr[1153]: restart bgpd process 1438 terminated due to signal 15
Jul 13 10:41:30 dp-router1 watchfrr[1153]: Warning: restart ripd child process 1515 still running after 20 seconds, sending signal 15
Jul 13 10:41:30 dp-router1 watchfrr[1153]: restart ripd process 1515 terminated due to signal 15
Jul 13 10:41:32 dp-router1 watchfrr[1153]: Warning: restart ospf6d child process 1542 still running after 20 seconds, sending signal 15
Jul 13 10:41:32 dp-router1 watchfrr[1153]: restart ospf6d process 1542 terminated due to signal 15
Jul 13 10:41:35 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 2050]: /usr/lib/frr/watchfrr.sh restart all
Jul 13 10:41:35 dp-router1 staticd[1216]: Terminating on signal
Jul 13 10:41:35 dp-router1 bfdd[1220]: VRF disable default id 0
Jul 13 10:41:35 dp-router1 bfdd[1220]: VRF Deletion: default(0)
Jul 13 10:41:35 dp-router1 ripngd[1200]: Terminating on signal
Jul 13 10:41:35 dp-router1 watchfrr[1153]: [EC 268435457] staticd state -> down : read returned EOF
Jul 13 10:41:35 dp-router1 zebra[1183]: [EC 4043309121] Client 'static' encountered an error and is shutting down.
Jul 13 10:41:35 dp-router1 zebra[1183]: [EC 4043309121] Client 'ripng' encountered an error and is shutting down.
Jul 13 10:41:35 dp-router1 zebra[1183]: [EC 4043309121] Client 'bfd' encountered an error and is shutting down.
Jul 13 10:41:35 dp-router1 watchfrr[1153]: [EC 268435457] bfdd state -> down : read returned EOF
Jul 13 10:41:35 dp-router1 watchfrr[1153]: [EC 268435457] ripngd state -> down : read returned EOF
Jul 13 10:41:55 dp-router1 watchfrr[1153]: Warning: restart all child process 2050 still running after 20 seconds, sending signal 15
Jul 13 10:41:55 dp-router1 watchfrr[1153]: restart all process 2050 terminated due to signal 15
Jul 13 10:43:00 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 3074]: /usr/lib/frr/watchfrr.sh restart all
Jul 13 10:43:00 dp-router1 watchfrr.sh: Cannot stop bfdd: pid file not found
Jul 13 10:43:00 dp-router1 watchfrr.sh: Cannot stop ripngd: pid file not found
Jul 13 10:43:00 dp-router1 watchfrr.sh: Cannot stop staticd: pid file not found
Jul 13 10:43:20 dp-router1 watchfrr[1153]: Warning: restart all child process 3074 still running after 20 seconds, sending signal 15
Jul 13 10:43:20 dp-router1 watchfrr[1153]: restart all process 3074 terminated due to signal 15
Jul 13 10:45:20 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 4103]: /usr/lib/frr/watchfrr.sh restart all
Jul 13 10:45:20 dp-router1 watchfrr.sh: Cannot stop bfdd: pid file not found
Jul 13 10:45:20 dp-router1 watchfrr.sh: Cannot stop staticd: pid file not found
Jul 13 10:45:20 dp-router1 watchfrr.sh: Cannot stop ripngd: pid file not found
Jul 13 10:45:40 dp-router1 watchfrr[1153]: Warning: restart all child process 4103 still running after 20 seconds, sending signal 15
Jul 13 10:45:40 dp-router1 watchfrr[1153]: restart all process 4103 terminated due to signal 15
Jul 13 10:49:44 dp-router1 watchfrr[1153]: [EC 100663303] Forked background command [pid 5302]: /usr/lib/frr/watchfrr.sh restart all
Jul 13 10:49:44 dp-router1 watchfrr.sh: Cannot stop bfdd: pid file not found
Jul 13 10:49:44 dp-router1 watchfrr.sh: Cannot stop staticd: pid file not found
Jul 13 10:49:44 dp-router1 watchfrr.sh: Cannot stop ripngd: pid file not found
Jul 13 10:50:04 dp-router1 watchfrr[1153]: Warning: restart all child process 5302 still running after 20 seconds, sending signal 15
Jul 13 10:50:04 dp-router1 watchfrr[1153]: restart all process 5302 terminated due to signal 15
admin@dp-router1:~$ restart vrrp
admin@dp-router1:~$ sh vrrp
VRRP information is not available
admin@dp-router1:~$ sh ip bgp neighbors
:...skipping...
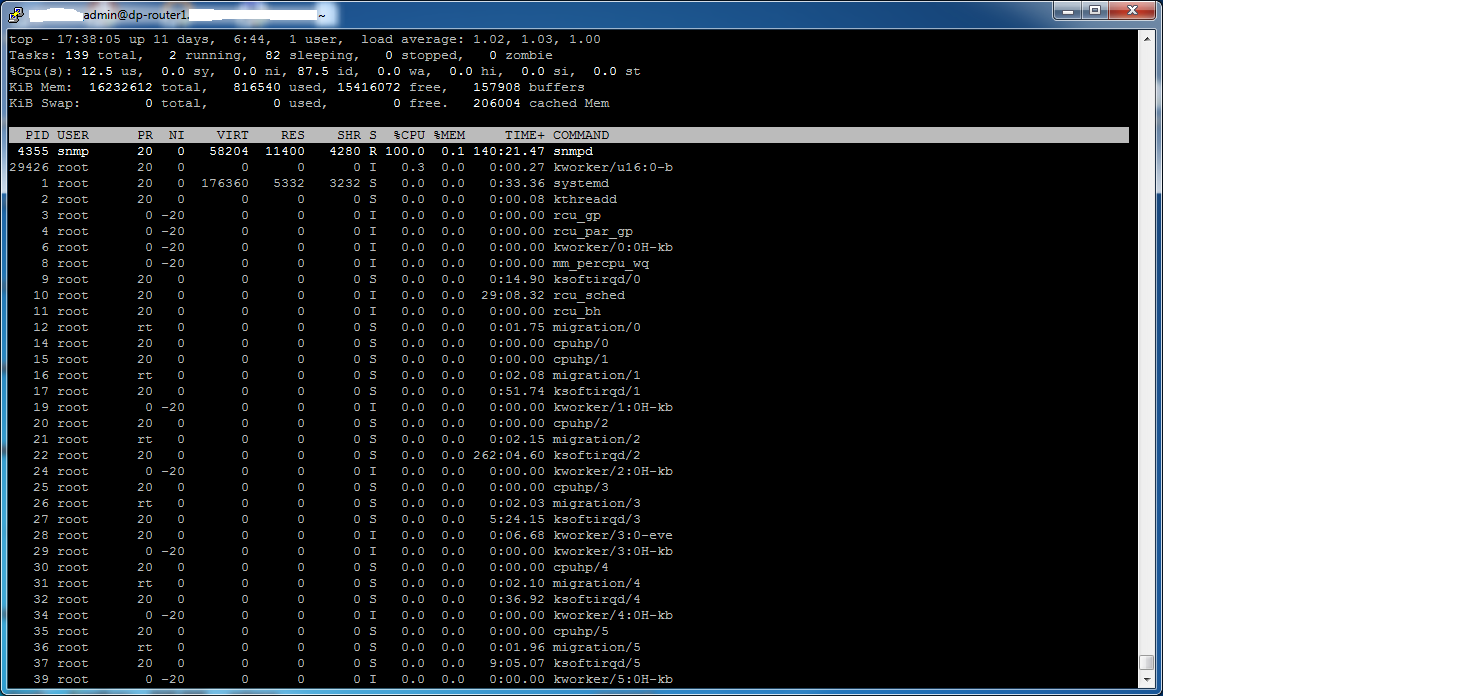
Top shows that snmpd process consumes 100% of the CPU.
The 1.2.7 LTS image has a fix described here already applied:
SNMPDOPTS='-LSed -u snmp -g snmp -I -ipCidrRouteTable,inetCidrRouteTable -p /run/snmpd.pid'
If you can help with this issue, you are welcome, but if you are using this image in the production, stop to do it, especially if you router is under heavy load of traffic.