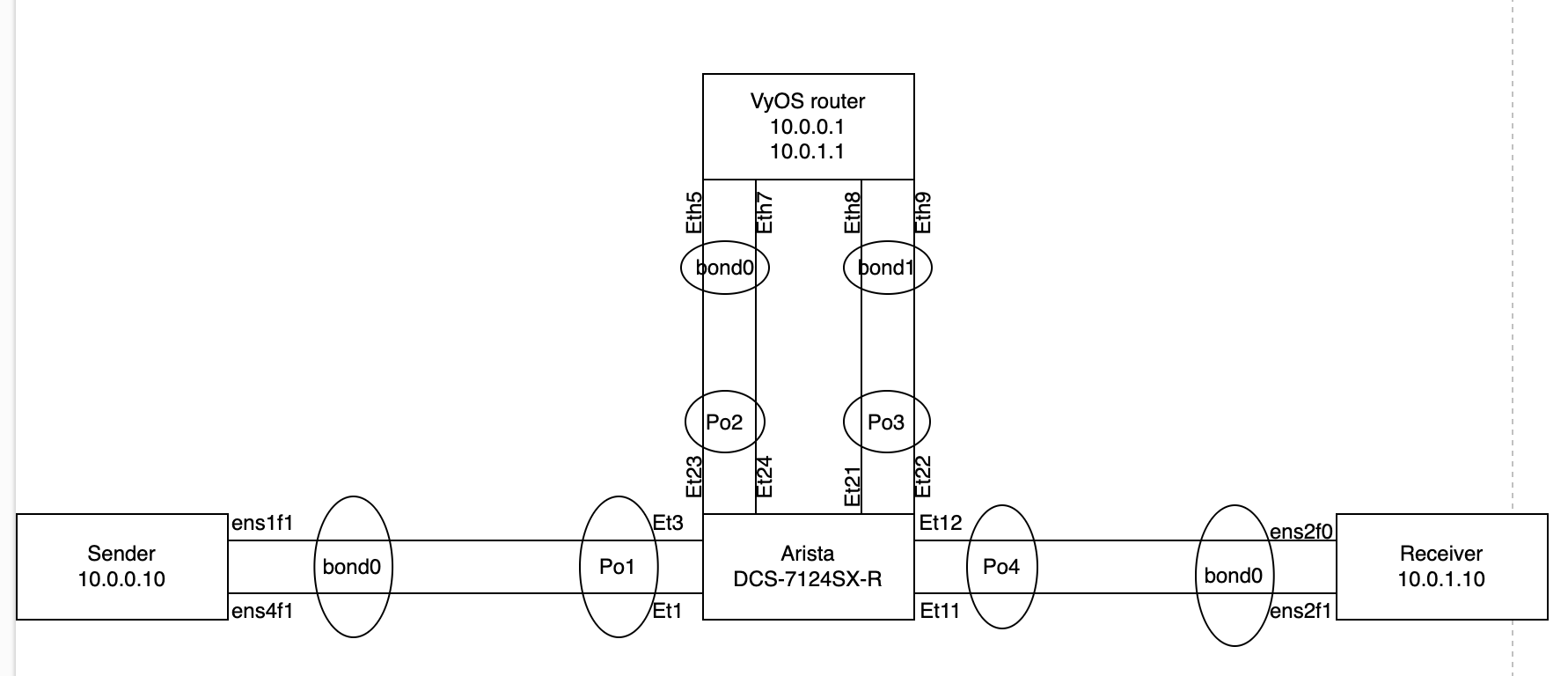
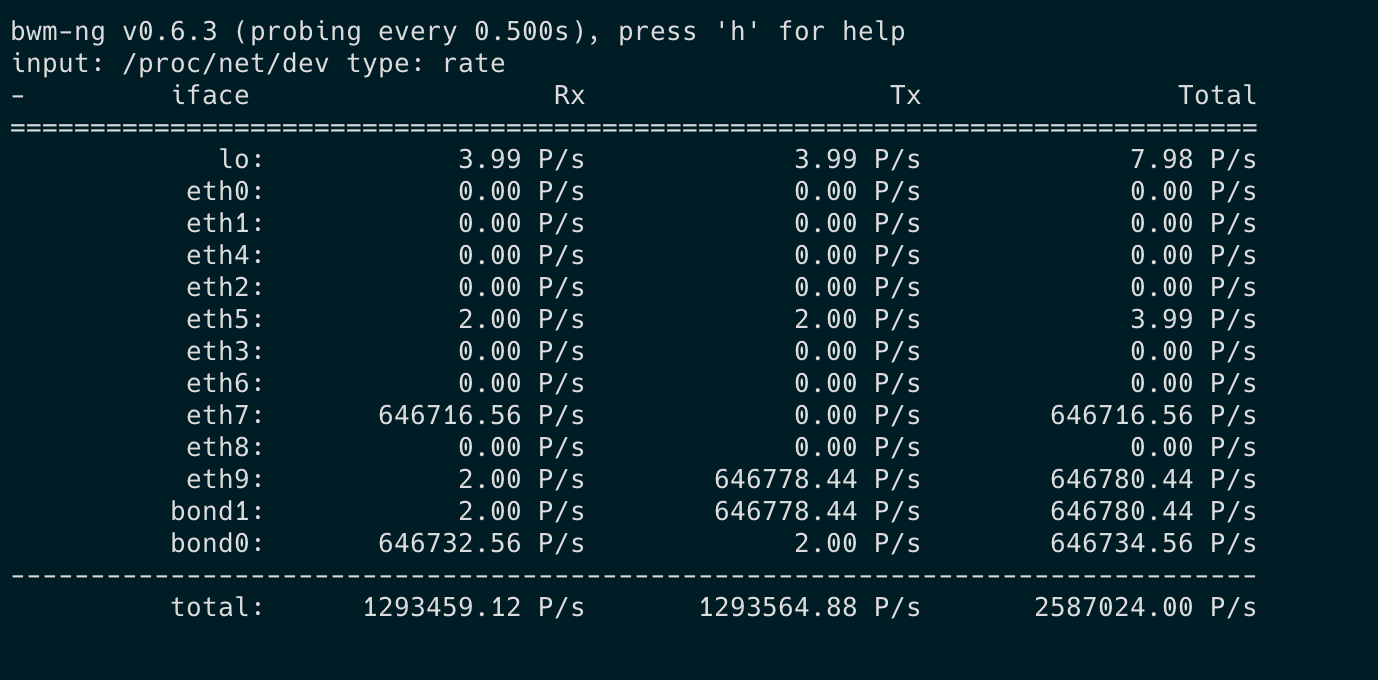
Even sending 600k pkt/s VyOS receives only 400k pkt/s. I can scale it up to 2M but the result is the same, VyOS is not able to forward about 20% of the packets. Also, there’s a huge increase in rx_no_dma_resources errors and fdir_miss(even tho there are no flow director rules enabled, and fdir_miss only increases when using UDP) If I remove the route to destination and scale up the pkt/s to 2M then there’s no loss(bonding the interface helped with this).
VyOS version is 1.3
VyOS is using 10G Intel 82599ES NICs with the latest driver version.
Bond mode 802.3ad. Tried to disable the bond and use single interfaces, same results.
Increased ring buffers to 4096 ethtool: -G rx 4096 tx 4096
Disabled flow control: ethtool -A autoneg off rx off tx off
Disabled lro: ethtool -K lro off
Turning off any interrupt limitations: ethtool -C rx-usecs 0
RSS enabled
Is this just the limit of your hardware? (this probably only uses a single core)
400k/s packets would translate into 4.8Gb/s throughput for normal sized packets (1500 MTU)
Is udp source port different for all subsequent packets? That’s not normal traffic, and it will involve more conntrack processing.
The source port is different. I also use separate destination IP addresses to ensure that RSS forwards the packets into several different queues. I agree that this is not regular traffic, but it still shows that there’s issue where a single core is not capable of receiving ~400k UDP pkt/s which seems very low, or am I wrong here? Conntrack and iptables are disabled.
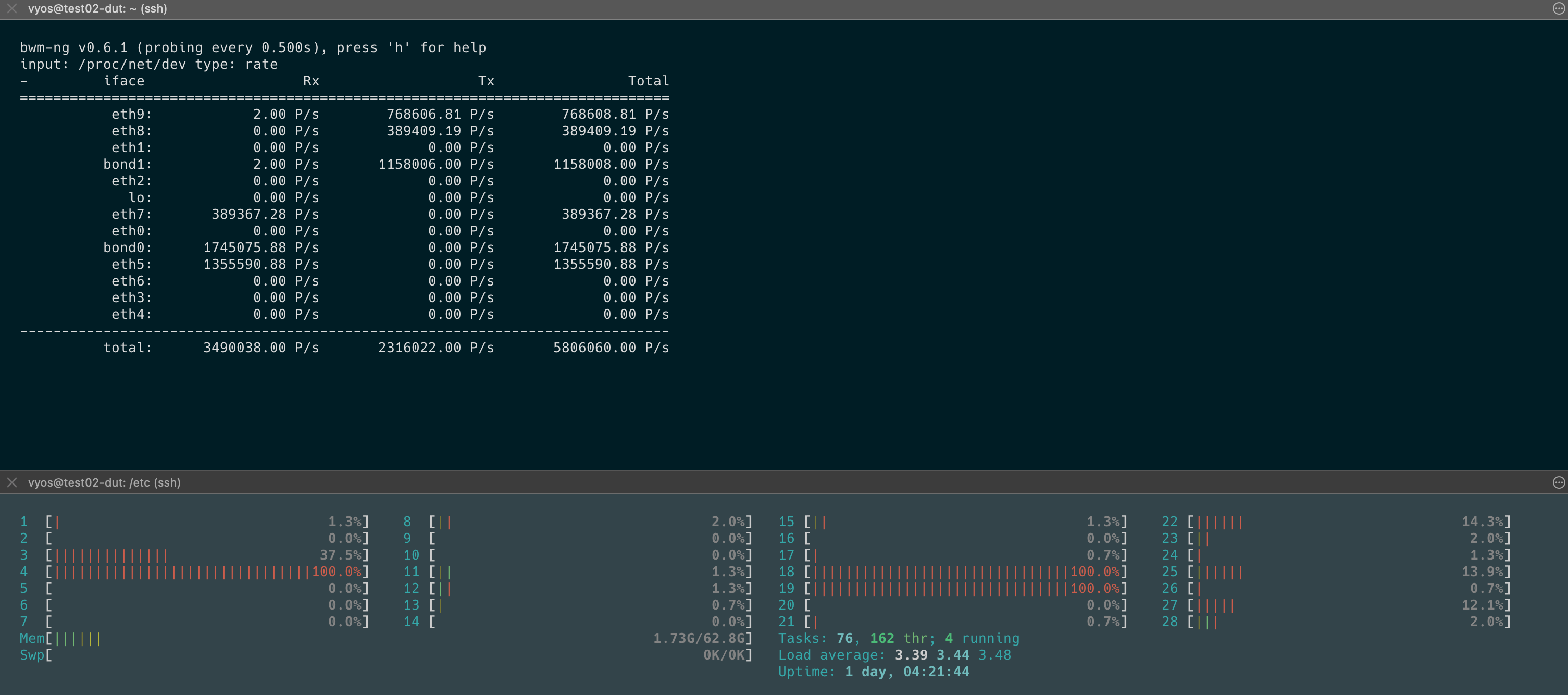
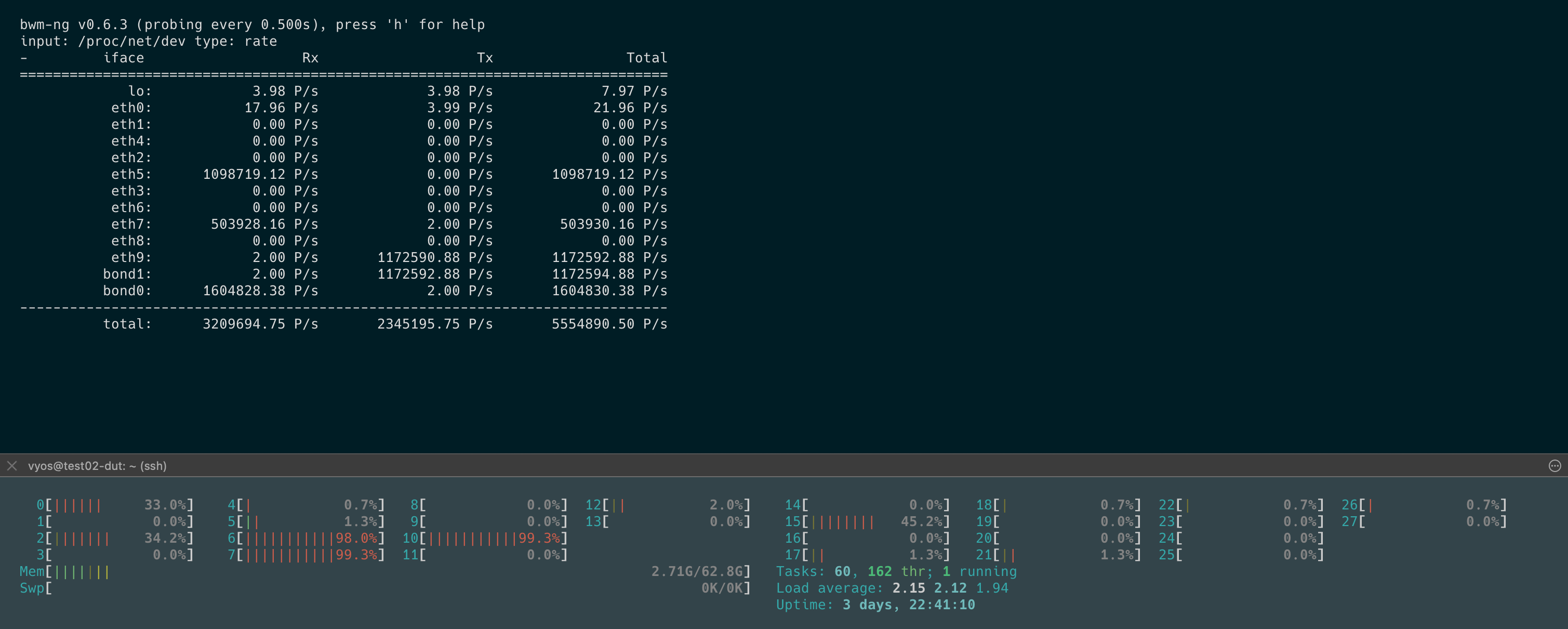
Offloading some of these features definitely helped with the RX side of things! Checking the CPU core load I can definitely see that load went from 100% to 25%. However, it looks like it’s not able to transmit all those received packets. This can be seen in bond0 and bond1 interfaces in the screenshot. The core which is responsible for TX is at 100% load. Do you have any other recommendations?
Any standard Linux tunning will help
The next step it’s turn off power save, disable logical cores and use fastpath bypass https://phabricator.vyos.net/T4502
Also bind interrupts to local numa/memory bank
Play with adapting interrupts
Power saving features and hyperthreading is disabled. Interrupts are mapped to the cores which are responsible for the NICs queues. I’ve tried playing with irqbalance but results are the same.
Also tried to increase net.core.netdev_max_backlog - didin’t helped.
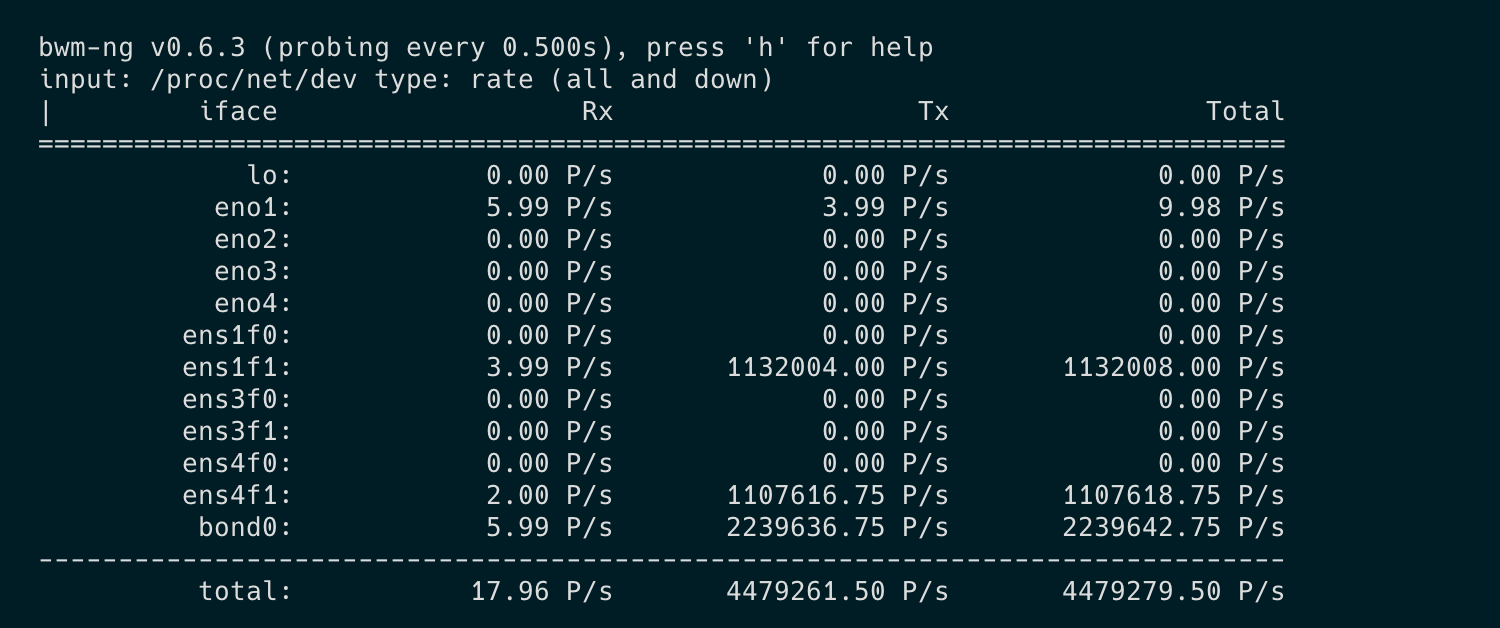
I just tried using the fast path and it’s amazing! I finally achieved the results I wanted. Here’s the pkt/s rate using 1 queue (1 core). It’s able to transmit everything it receives.
Are there any fallbacks using fastpath? After reading some papers I noticed that fast path does not work with fragmented packets, which makes sense, since fast path is using conntrack system.
Good stuff! Would you terribly mind sharing the steps you’ve taken to achieve your goals? It will help people with similar goals to find this topic (e.g. using the boards’ search function). As a performance related topic, this is valuable input for scaling in larger environments
Are you still testing with “unique” packets (i.e. , not belonging to existing connecting, new source port and/or dest address) ?
Then I doubt fast path can really help, as 1st packet is handled in software.
Below is the short summary which helped me to achieve better performance:
Sender is sending >600k pkt/s on 1 flow(10.0.0.10:11404-> 10.0.1.10:4321). Vyos router was not able to receive all these packets. It could do up to 500k pkt/s. Enabling RPS offload allowed the router to receive all of these packets. set interfaces ethernet ethX offload rps
The test is done using a single flow, 10.0.0.10:11404 → 10.0.1.10:4321
However, scaling it up to 3 flows: 10.0.0.10:11404 → 10.0.1.10:4321, 10.0.1.11:4321, 10.0.1.12:4321 I get bad results, router is still capable of receiving all the packets, but has some issues forwarding them.
My goal is to make the router forward atleast 2M pkt/s
edit: apparently I reached the link capacity limit! had to reduce the payload size and I am able to TX 2M pkt/s. However there’s some loss, will dig deeper.
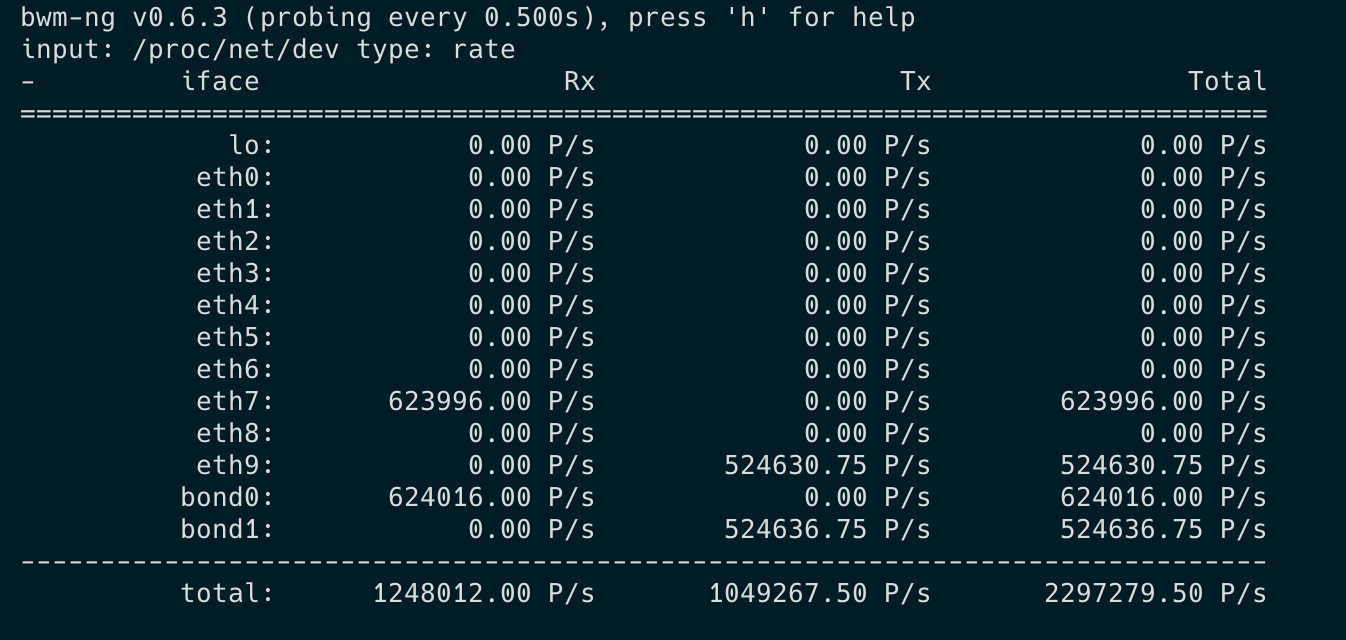
I’ve enabled XDP and I am even happier with the results. I can see some rx_no_dma_resource errors at 5-6M pkt/s, but at a very slow rate. Scaling it up to 20 flows, I reached the 10M pkt/s zone.
I am not able to see those flows in conntrack, I assume it’s because XDP works at the lowest level, even before netfilter’s flowtable or even taps. Would that be correct? If yes, then flowtable is not even needed? Maybe there’s VyOS documentation on how exactly it’s using the XDP?
hi there, what to do if I get this error?
nft add flowtable ip filter f { hook ingress priority 0; devices = { eth4, eth2 }; counter; }
Error: No such file or directory
add flowtable ip filter f { hook ingress priority 0; devices = { eth4, eth2 }; counter; }
^^^^^^