What is the best method for my BGP routers to share external BGP routes to my OSPF routers ?
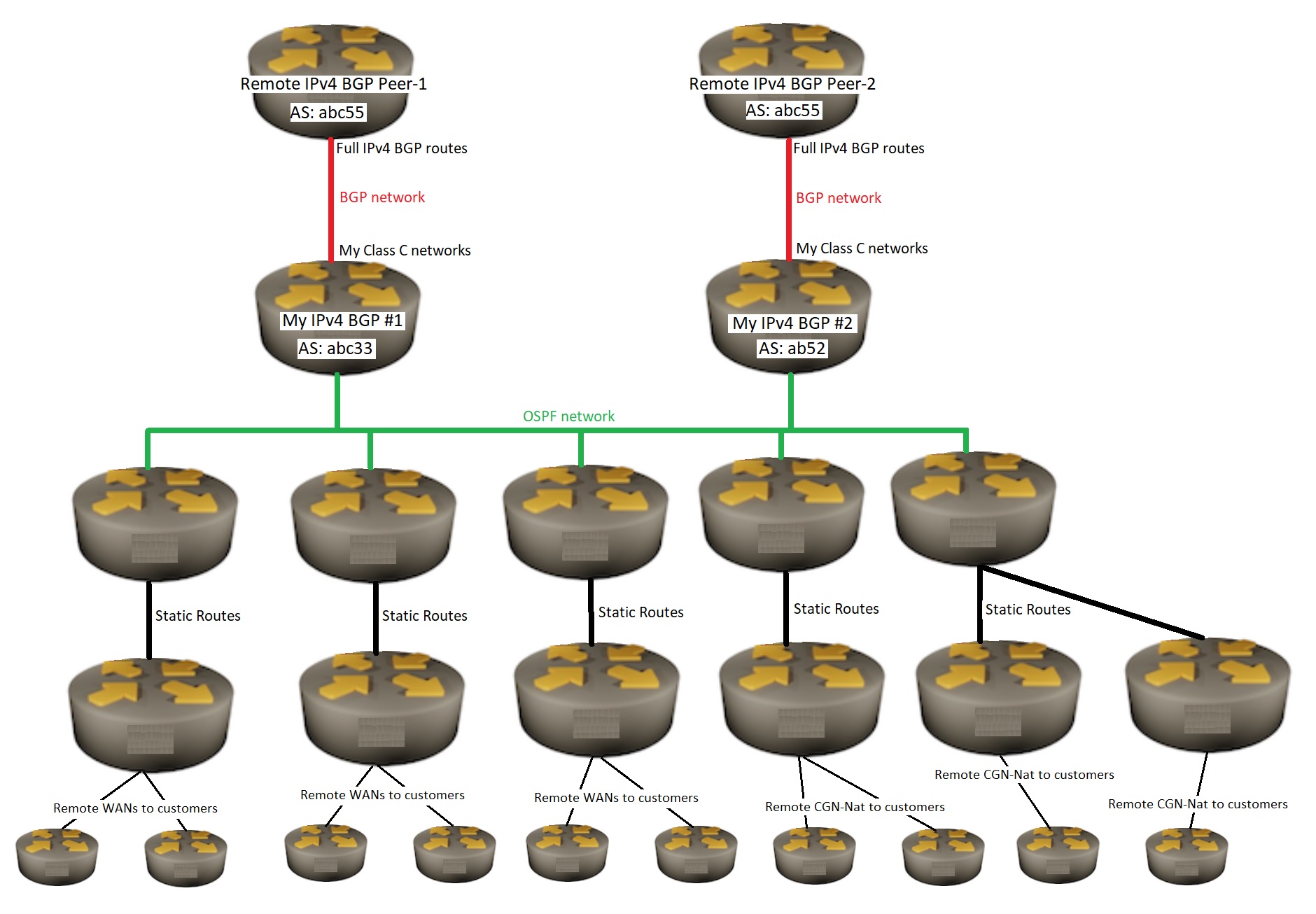
I have two IPv4 BGP routers. Each of my BGP routers have different upstream BGP peers.
Both of my two BGP routers do not know any BGP routes information from my other BGP router.
Both of my BGP routers know my OSPF routes ( but do not put anything into my OSPF routers ).
I have multiple OSPF routers. All of my OSPF routers know the live-IP routes for all other OSPF routers.
None of my OSPF routers know any BGP routes.
All of my OSPF routers have a single default route to only one or the other of my BGP routers.
All of my OSPF routers use static routes to the rest of my other routers.
Some of my other non-BGP and non-OSPF routers are used for CGN-NAT , live-IP-routers and Wans/Lans to my customers.
My question - What is the best method for my OSPF routers to be able to get to the Internet if one of my BGP routers dies or drops/looses the BGP tables from either external upstream BGP peer ?
-
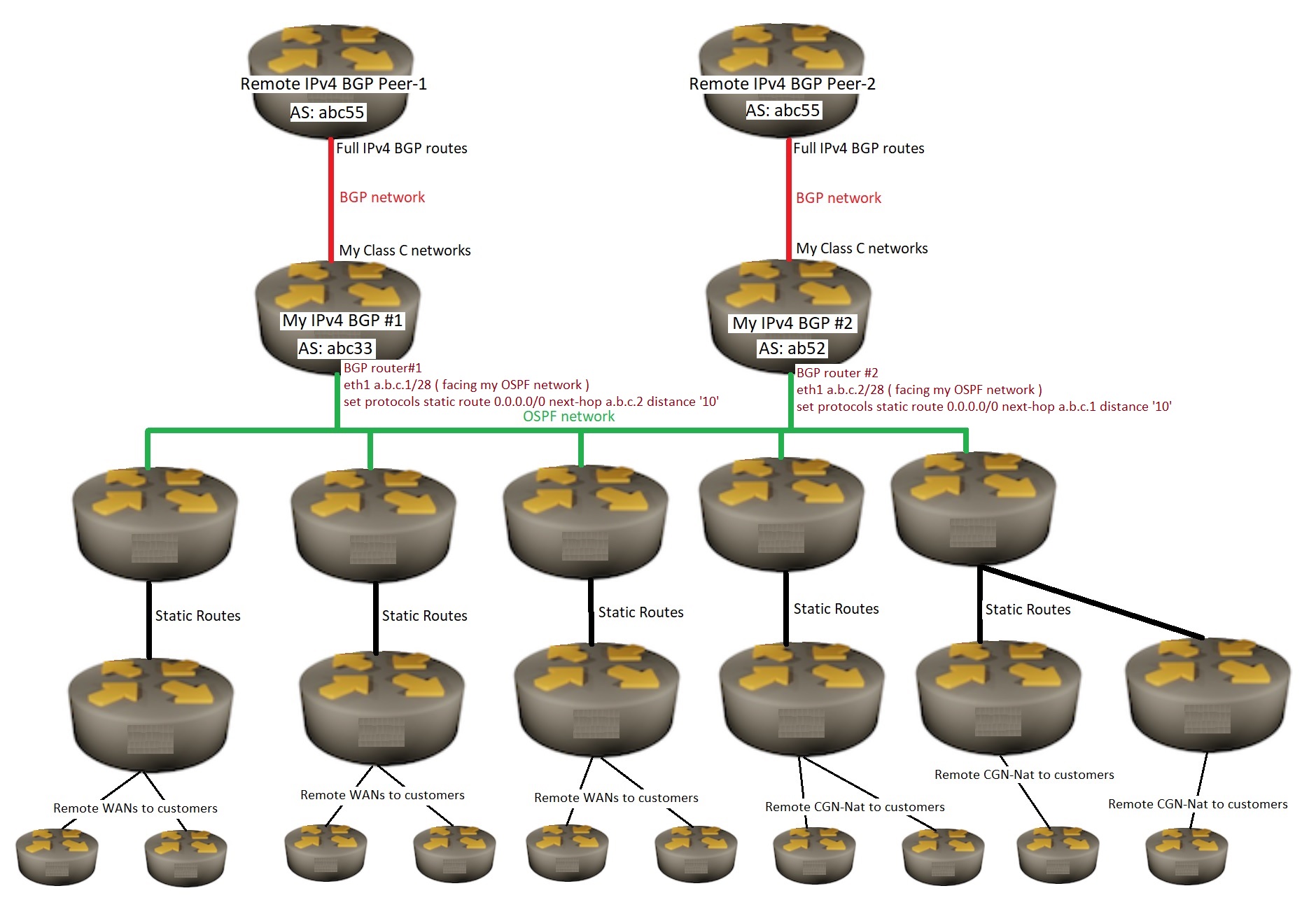
Should I have both of my BGP routers redistribute full BGP routing tables to my OSPF routers ? This would then introduce all BGP routes twice into my OSPF routing table.
-
I wish to configure something that is a best path out from my OSPF routers to the Internet and some redundancy if/when one of my BGP routers has a problem.
-
is there a way for each of my two BGP routers to put a single default route into my OSPF network ?
** I included a simple network drawing of what I have.
Red lines are BGP routes only.
Green lines are OSPF routes only.
Black lines are static routes only.
I’m open for ideas (OSPF , iBGP , something else … )
Thank you for ideas
North Idaho Tom Jones