Im running 1.2.0-rolling+201902250337 currently. I have a couple instances running in AWS, one in particular which is the hub, in a hub-spoke VPN toplogy (IPSEC iKev2), seems to run out of memory after 1-2 weeks. Was not an issue on a much earlier version of 1.2.0 (not sure which version).
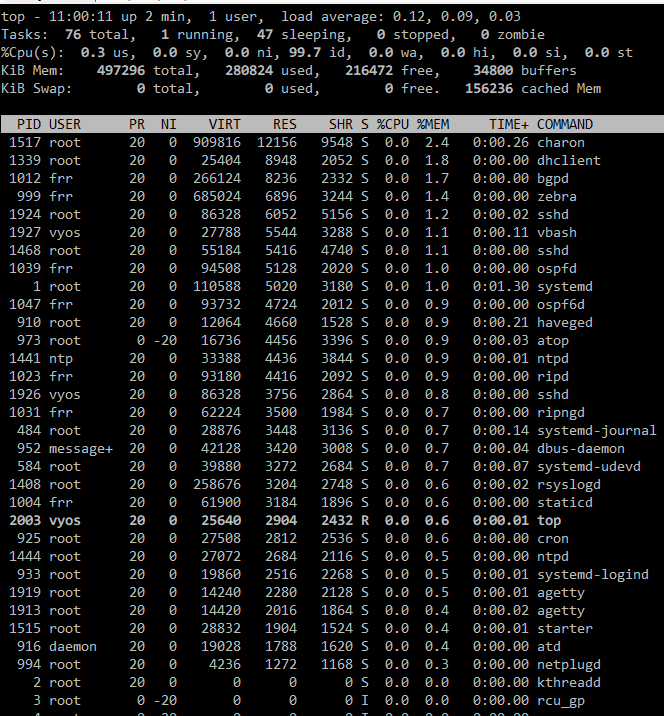
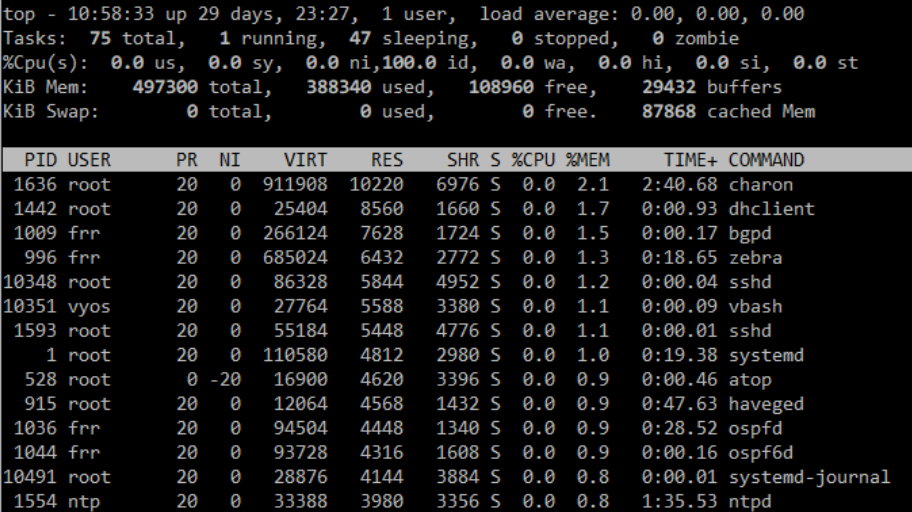
Attached are screenshots of TOP, also included logs output, which shows oom killing off processes.
systemd-journal seems to keep going up in usage? Dont know if that is the culprit. Also excuse my lack of Linux knowledge, but in the TOP screenshot which lists processes by descending memory usage, should the sum of RES + cached + buffers not equal ‘used’?
Hello, @kav!
Theoretically, systemd-jounal memory usage must be limited to about 10% of /run partition.
Send, please, a whole content of /var/log/atop/ directory after you catch memory leak next time.
I have attached the contents of this instance /var/log/atop/ - note I had to change file extension from zip to log to allow attachment (its a bunch of files).
I see, that systemd-journald use too much of memory in your case. But, I can’t reproduce this in short-time period, even by generating flood into log.
Give me, please, also output of next commands:
Hello All
I have similar problem:
To end of October 2018 I used VYOS 1.8,
from November 2018 to February VYOS 1.2-RC4,
from March I build version 1.2 crux in docker (from guide on Wiki )
My VYOS is running on KVM.
Please look at zabbix monitoring:
Thank you, @kav!
Try this workaround, and check if memory stops to leak:
set system task-scheduler task logging-restart executable arguments 'restart systemd-journald'
set system task-scheduler task logging-restart executable path '/bin/systemctl'
set system task-scheduler task logging-restart interval '1d'
@Rafal, could you check which exactly process use memory in your case?
Ive been monitoring the memory consumption of 4 instances running the same version and the odd thing I noticed is that after the first reboot (I think its the first since deployment), memory consumption is much lower and fairly stable now.
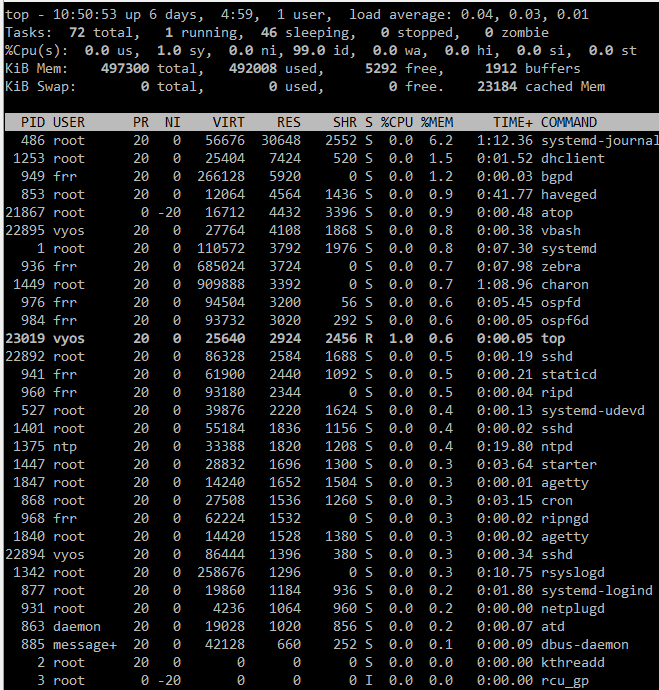
So i’ve had this running for quite a few days (the workaroud @zsdc posted) and it does indeed seem to keep the memory consumption of systemd-journal low - but the consumption of memory overall is still high and creeps up. See image, when I add the RES + cached, it does not add up anywhere near used amount.
Also, this particular instance is running as the hub in a hub and spoke VPN topology. However the spokes are all stable in memory usage and have over 150MB available in cached. Is it normal for a few extra tunnels to consume that much more memory on the hub?
EDIT: Ok so I dumped the data into excel and added them up.
RES = 116MB
Buffers = 13MB
Cached = 62MB
Total = ~190MB
So ‘used’ should be roughly 190MB right? But its showing as 482MB, off by 292MB!
When I do the same math on another Ubuntu server I have, the numbers add up as expected (off by 2-3%).
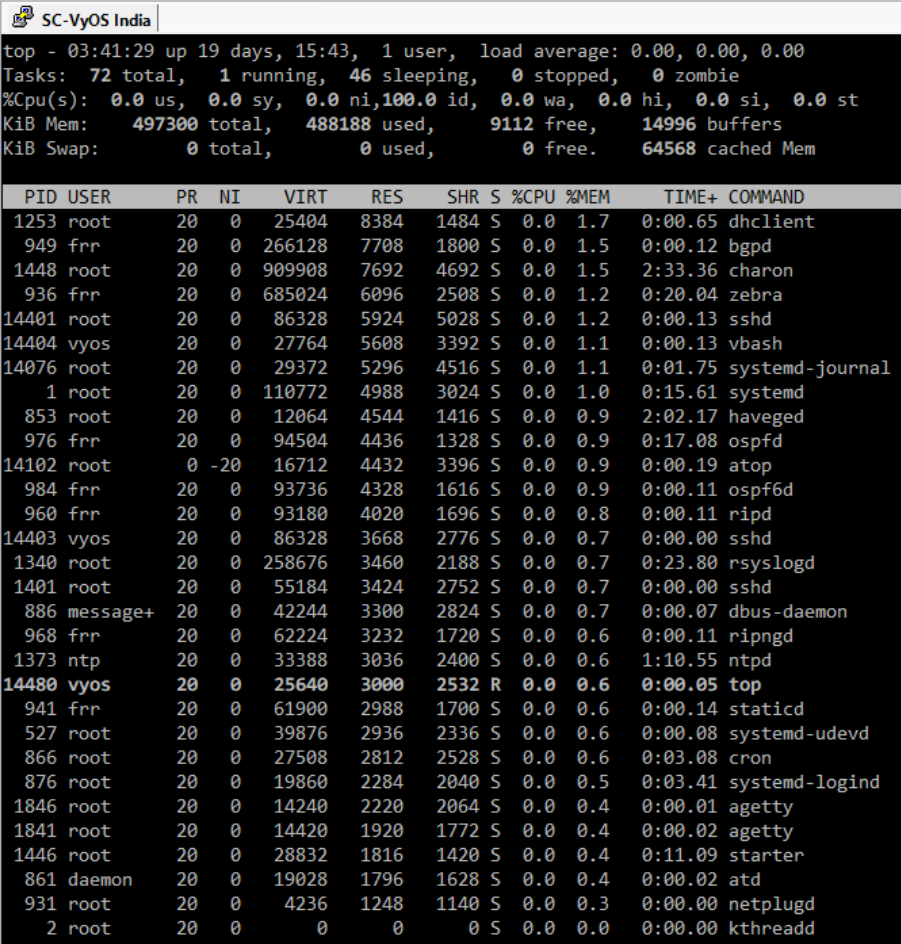
Now the same math on another VyOS instance that only has one tunnel and seems to stable:
RES = 164MB
Buffers = 90MB
Cached = 149MB
Total = ~403MB
Its showing 487MB used, so its off by ~84MB, so no where near as off as the ‘bad’ VyOS instance.
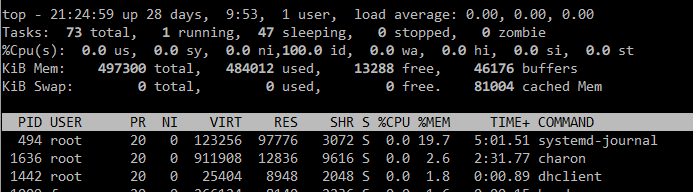
Ok so quick update for those that might experience the same issue… Have upgraded to a newer rolling release: 1.2.0-rolling+201903250337
Issue seems resolved, the instance without any config change has way more free memory and also the systemd-journal has never gone above 1% on memory consumption.